Sơ đồ điện của mạch điều tốc
28/04/2023
@ Saigon
Mining Rig

run.bat:loop
C:\Users\CHANGE_ME\Desktop\Software\dynexsolve_windows2.2.5\DynexSolveVS.225.exe ^
-mallob-endpoint https://dnx.sg.ekapool.com ^
-mining-address WALLET_ADDRESS ^
-stratum-url POOL_URL -stratum-port POOL_PORT -no-cpu -multi-gpu ^
-stratum-password WORKER_NAME -adj 1.0898 -sync
goto loop
:exitloopExample:
:loop
C:\Users\LacLongQuan\Desktop\Software\dynexsolve_windows2.2.5\DynexSolveVS.225.exe ^
-mallob-endpoint https://dnx.sg.ekapool.com ^
-mining-address XwnTnXV7cSEQszHqM3xihWZp6MiP6n8vqggLFH15VMEBDnpkBKnv1Cz7wn5L18uVrwMDFhdhB2fV3fSTZ7MexKDJ1ZgGx9ZCC ^
-stratum-url dnx.sg.ekapool.com -stratum-port 19666 -no-cpu -multi-gpu ^
-stratum-password LAC-LONG-QUAN -adj 1.0898 -sync
goto loop
:exitloopSRBMiner-MULTI.exe ^
--algorithm dynex ^
--disable-cpu ^
--gpu-id 0 ^ :: enable/disable gpu
--mallob-endpoint https://dnx.sg.ekapool.com ^
--pool dnx.sg.ekapool.com:19666 ^
--wallet WALLET-ADDRESS
--password WORKER-NAMEExample:
setx GPU_MAX_HEAP_SIZE 100
setx GPU_MAX_USE_SYNC_OBJECTS 1
setx GPU_SINGLE_ALLOC_PERCENT 100
setx GPU_MAX_ALLOC_PERCENT 100
setx GPU_MAX_SINGLE_ALLOC_PERCENT 100
@echo off
cd %~dp0
cls
SRBMiner-MULTI.exe ^
--algorithm dynex ^
--disable-cpu ^
--gpu-id 0 ^
--mallob-endpoint https://dnx.sg.ekapool.com ^
--pool dnx.sg.ekapool.com:19666 ^
--wallet XwnTnXV7cSEQszHqM3xihWZp6MiP6n8vqggLFH15VMEBDnpkBKnv1Cz7wn5L18uVrwMDFhdhB2fV3fSTZ7MexKDJ1ZgGx9ZCC ^
--password AU-CO
pauseoc.batnvidia-smi -lgc 1760
nvidia-smi -lmc 5000
nvidia-smi -pl 135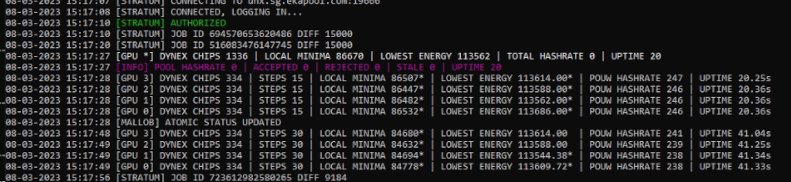
In addition, install the following dependencies if need.
01-mine-etica.bat@echo off
pushd %~dp0
for %%X in (dotnet.exe) do (set FOUND=%%~$PATH:X)
if defined FOUND (goto dotNetFound) else (goto dotNetNotFound)
:dotNetNotFound
echo .NET Core is not found or not installed,
echo download and install from https://www.microsoft.com/net/download/windows/run
goto end
:dotNetFound
:startMiner
DEL /F /Q SoliditySHA3Miner.conf
SoliditySHA3Miner.exe ^
allowCPU=false ^
allowIntel=false ^
allowAMD=false ^
allowCUDA=true ^
abiFile=0xBTC.abi ^
contract=0xB6eD7644C69416d67B522e20bC294A9a9B405B31 ^
overrideMaxTarget=26959946667150639794667015087019630673637144422540572481103610249216 ^
pool=http://eticapool.com:8081 ^
address=0xE58796150958032349A32f20031645a3850Fe92C
if %errorlevel% EQU 22 (
goto startMiner
)
:end
pause02-oc-etica.batnvidia-smi -lgc 1850
nvidia-smi -lmc 810
nvidia-smi -pl 220
pause01-mine-etica.bat & 02-oc-etica.bat.
Bài viết này được viết để hỗ trợ cho các dàn đào sử dụng hệ điều hành Window 10. Ý kiến cá nhân, tôi không thích sử dụng các hệ điều hành chuyên dụng ví dụ như Minerstat OS, tôi thích sử dụng Minerstat Window hơn.

AHCIEnabledUpon Request (Mặc định)Force BIOS (Mặc định)UEFI and LegacyDo not lauch (Mặc định)UEFILegacy (Mặc định)UEFI (Mặc định)DisabledPower OnUnattended AccessNever NotifyHigh Performance
NeverNever32,000 MB32,000 MBAdjust for best performance
execTrước tiên cần giải thích hành vi của exec. Dưới đây là ví dụ của file có tên là script.sh. Trong file này, nó sẽ gọi child_script.sh
#!/bin/bash
...
...
...
./child_script.shGiả sử như là child_script này chạy khá lâu, lâu đến mức chúng ta có thể mở một terminal khác và rồi liệt kê danh sách những
process nào đang chạy. Chúng ta sẽ thấy có hai process.
script.shchild_script.shPhân tích thêm một chút là mặc dù script.sh đã chạy xong phần việc của nó, giờ đây nó kích hoạt child_script.sh, phần
code/chức năng lúc này đang được thực thi là năm trong child_script.sh. Lưu ý một chút là mặc dù để tên là child_script.sh
tuy nhiên đây cũng có thể là một đoạn script ngang cấp với script.sh, chỉ đơn giản là script này chạy trước, cái kia chạy sau,
script này gọi script kia.
Khi nhìn nhận ở góc độ này, chúng ta có thể nhận ra rằng việc nhận được danh sách process đang chạy có 2 process dành cho
script.sh và child_script.sh không phải lúc nào cũng là phương án tốt nhất.
Một cách tiếp cận khác đó là khi script.sh đã chạy xong, process dành cho nó sẽ bị khai tử, và khi liệt kê danh sách các
process đang chạy, chúng ta sẽ chỉ thấy process dành cho child_script.sh mà thôi.
Để làm được điều này, ta sẽ cần sử dụng exec. script.sh sau khi viết lại và sử dụng exec sẽ trông như sau:
#!/bin/bash
...
...
...
exec ./child_script.shchild_script.sh là script cuối cùng cần phải kích hoạt sau khi chạy script.sh. Không sử dụng exec ở giữa file script
trừ trường hợp muốn cắt ngang script.sh.
Nếu vô ý sử dụng exec ở giữa file script, đoạn code nằm sau exec sẽ bị bỏ qua ngay cả khi child_script.sh đã xử lý xong.
Lý do là vì ngay khi sử dụng exec, process dành cho script.sh đã bị khai tử, thành ra, nó không có cơ sở để thực thi những
đoạn code nằm sau.
Trong một thư mục bất kỳ hãy tạo nội dung hai file script.sh và child_script.sh như sau:
script.sh
#!/bin/zsh
echo "this is script.sh"
sleep 1
./child_script.shchild_script.sh
#!/bin/zsh
echo "this is child_script.sh"
sleep 20Tình huống hiện tại, exec không được sử dụng, khi chạy script.sh ; Ta sẽ thấy có hai process.
Sử dụng lệnh ps -a để xem danh sách process.
script.shchild_script.sh![[1] Không sử dụng exec](/image/posts/2022-07-27-Phan-tich-exec-trong-shell-script/1.png)
Và tiếp theo, khi thêm exec vào trước ./child_script.sh trong file script.sh, ta sẽ chỉ thấy có một process là:
child_script.sh![[2] Sử dụng exec](/image/posts/2022-07-27-Phan-tich-exec-trong-shell-script/2.png)
Bài phân tích này kết thúc ở đây, chúc các bạn tìm được cách tiếp cận hợp lý khi viết script trong từng trường hợp cụ thể.
Cảm ơn đồng nghiệp của tôi là anh Duy đã dành thời gian quý báu của mình để giúp tôi hiểu thêm về exec.
Tôi gặp vấn đề khó chịu này khi sử dụng cùng lúc 2 tài khoản Microsoft Teams trên Window 10. Lỗi này xảy ra khi tôi chuyển đổi giữa hai account. Để khắc phục vấn đề này các bạn hãy làm như sau.
![[1] We're sorry—we've run into an issue.](/image/posts/2022-07-19-Cach-sua-loi-Microsoft-Teams/1.png)
.
Tôi gặp vấn đề khó chịu này khi sử dụng cùng lúc 2 tài khoản Microsoft Teams trên Window 10. Lỗi này xảy ra khi tôi chuyển đổi giữa hai account. Để khắc phục vấn đề này các bạn hãy làm như sau.
%LocalAppData%\Microsoft\Teams\currentLocalAppData là enviroment variable có giá trị chính là C:\Users\nguye\AppData\Local\
Tùy vào tên username mà giá trị này có thể thay đổi. Tuy nhiên khi paste
%LocalAppData%\Microsoft\Teams\current vào File Explorer, File Explorer sẽ tự trỏ vào thư mục cần thiết.
![[2] File Explorer](/image/posts/2022-07-19-Cach-sua-loi-Microsoft-Teams/2.png)
compatibility mode của file Teams.exe thành Window 8.![[3] Teams.exe Properties](/image/posts/2022-07-19-Cach-sua-loi-Microsoft-Teams/3.png)
Đã xong, bạn có thể vào lại Microsoft Team và tận hưởng thành quả!
In this post, I would like to introduce a way to quickly setup SSL certificate for any website with https://www.ssls.com/
To generate private key and certificate signing request, use the following command with a note of these parameters.
your_domain.pemyour_domain.csr$ openssl req -new -newkey rsa:2048 -nodes \
-keyout your_domain.pem \
-out your_domain.csr \
-subj /CN=www.hexalink.xyz![[1] Submit Certificate Signing Request](/image/posts/2022-06-28-How-to-install-ssl-for-nginx-with-ssls.com/1.png)
After the download process, there gonna be three file
![[2] Download Certificate from ssls.com](/image/posts/2022-06-28-How-to-install-ssl-for-nginx-with-ssls.com/2.png)
your_domain.crt and your_domain.ca-bundle in order with your favorite text editor.Please becareful while do concat
-----END CERTIFICATE----------BEGIN CERTIFICATE-----
.crt before .ca-bundleWe can name concated file as ssl-bundle.crt.
After this time, there are two file that you need to bring to the nginx server.
your_domain.pemssl-bundle.crt) which is a concat version of your_domain.ca-bundle and your_domain.crt in order.Before configure nginx.conf file at /etc/nginx, it’s a need to copy private key file and certificate file to /etc/pki/nginx/.
You can choose different directory, but you need to make it up to date in the nginx.conf file.
This is an example of nginx config file, the most important attribute are:
listen 443;ssl on;ssl_certificate /etc/pki/nginx/ssl-bundle.crt;ssl_certificate_key /etc/pki/nginx/your_domain.pem;server {
listen 443 ssl; <-----
listen [::]:443 ssl; <-----
http2 on;
server_name abc.xyz; <-----
root /usr/share/nginx/abc.xyz.html; <-----
ssl_certificate "/etc/pki/abc.xyz/www_abc_xyz.bundle.crt"; <-----
ssl_certificate_key "/etc/pki/abc.xyz/www_abc_xyz.pem"; <-----
ssl_session_cache shared:SSL:1m;
ssl_session_timeout 10m;
ssl_ciphers PROFILE=SYSTEM;
ssl_prefer_server_ciphers on;
charset UTF-8;
# Load configuration files for the default server block.
include /etc/nginx/default.d/*.conf;
}After finished editing, restart nginx server with systemctl restart nginx and enjoy.
# XMRig configuration file config.json
{
"api": {
"worker-id": "worker-x"
},
"http": {
"enabled": true,
"host": "0.0.0.0",
"port": 8080,
"access-token": null,
"restricted": true
},
"autosave": false,
"opencl": false,
"cuda": false,
"pools": [
{
"coin": "monero",
"algo": "rx/0",
"url": "pool.hashvault.pro:443",
"user": "MONERO_ADDRESS_HERE",
"pass": "worker-x",
"tls": true,
"keepalive": true,
"nicehash": false
}
],
"randomx": {
"1gb-pages": true
},
"cpu": {
"enabled": true,
"huge-pages": true
}
}
By default, running xmrig to mine Monero will got 1GB PAGES disabled eventhough config.json has been configured.
![[1] XMRig without 1GB pages supported.](/image/posts/2022-05-30-xmrig-support-1GB-Page-on-Fedora/1.png)
While running xmrig, you can caught the following log.
[2021-03-15 15:14:59.732] randomx failed to allocate RandomX dataset using 1GB pagesThe solution is to edit grub file located at /etc/default/grub with the following config:
GRUB_CMDLINE_LINUX_DEFAULT="hugepagesz=1G hugepages=3"Then, update grub.cfg with this command and do reboot.
grub2-mkconfig -o /boot/grub2/grub.cfgFinally, run your xmrig with sudo and enjoy!
![[2] XMRig with 1GB pages supported.](/image/posts/2022-05-30-xmrig-support-1GB-Page-on-Fedora/2.png)
Bài lược trích của thầy giáo Ngô Minh Đức dưới đây hi vọng sẽ là lời giải thích gần gũi về ý nghĩa và ứng dụng thực tiễn của đạo hàm.
Một năm sau ngày ra trường, bạn đi họp lớp và gặp lại đứa bạn ngồi cùng bàn. Quá bất ngờ vì cô bạn trở nên xinh đẹp, tự tin, khiến bạn phải thốt lên: “Mới có một năm, sao bạn thay đổi nhiều quá vậy?”.
Câu chuyện đơn giản trên đã ẩn chứa ý tưởng đạo hàm trong đó. Khi một điều gì đó thay đổi, nó có thể thay đổi nhanh hay chậm, đạo hàm sẽ cho ta biết “tốc độ thay đổi” của đại lượng đó. Nhờ ý nghĩa này, đạo hàm trở thành công cụ vô cùng quan trọng, ở bất cứ đâu có sự thay đổi, chúng ta sẽ biết được nó thay đổi như thế nào bằng đạo hàm.
Cụ thể, nếu hàm số đang tăng đạo hàm sẽ dương, tăng càng nhanh thì đạo hàm càng lớn. Ngược lại, hàm số đang giảm, đạo hàm sẽ âm và âm càng nhiều khi hàm số giảm càng nhanh.
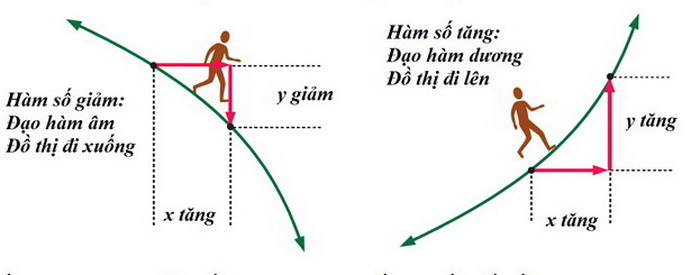
Ở khía cạnh thực tiễn, nếu bạn là nhà kinh tế và muốn biết tốc độ tăng trưởng kinh tế nhằm đưa ra những quyết định đầu tư chứng khoán đúng đắn; nếu bạn là nhà hoạch định chiến lược, muốn có thông tin về tốc độ gia tăng dân số ở từng vùng miền; hoặc muốn xác định tốc độ phản ứng hóa học, tính toán tốc độ, gia tốc của chuyển động… Đạo hàm sẽ là thứ mà bạn cần.
Rất đơn giản! Đầu tiên bạn cần có hàm số mô tả đại lượng đang quan tâm và sau đó chỉ cần đạo hàm nó. Còn tính đạo hàm như thế nào thì sách giáo khoa đã chỉ dẫn rõ ràng và chi tiết, đơn giản hơn chúng ta có thể nhờ máy tính làm giúp.
Đạo hàm còn những ứng dụng tuyệt vời khác. Một trong số đó là tìm xem hàm số sẽ đạt được giá trị lớn nhất hay nhỏ nhất ở đâu, để từ đó tối ưu hóa các hoạt động khác nhau trong cuộc sống.
Khi một hàm số đang tăng (đạo hàm dương) rồi bất chợt chuyển sang giảm (đạo hàm âm), nó đã đi qua vị trí mà tại đó hàm số đạt giá trị cực đại và vị trí này cũng chính là nơi có đạo hàm bằng 0 (có thể có ngoại lệ nhé!). Tương tự cho trường hợp hàm số đạt được giá trị cực tiểu.
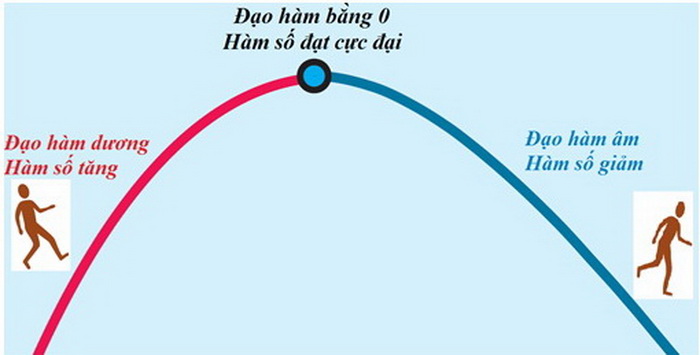
Từ nhận xét này, bằng cách tìm những chỗ mà đạo hàm bằng 0, người ta có thể biết một đại lượng sẽ đạt giá trị lớn nhất hay nhỏ nhất ở đâu để từ đó có thể tối ưu hóa nó theo mong muốn của mình.
Sử dụng đặc trưng này của đạo hàm, các công ty có thể tính được số sản phẩm nên sản xuất để đạt được lợi nhuận cao nhất. Các kĩ sư sẽ biết phải thiết kế một hộp sữa hay một lon nước ngọt như thế nào, với lượng nguyên liệu có sẵn, để có một hộp sữa chứa được nhiều sữa nhất…
Cụ thể, ta cần có hàm số mô tả lợi nhuận theo số lượng sản phẩm hoặc hàm số mô tả thể tích hộp sữa theo kích thước thiết kế. Đạo hàm sẽ giúp ta tìm xem các hàm số này đạt giá trị lớn nhất tại đâu. Đó chính là lựa chọn tối ưu cho nhà sản xuất.
Ở các sách giáo khoa nước ngoài, họ luôn nhấn mạnh cho học sinh rằng ý nghĩa quan trọng nhất của đạo hàm là cho biết tốc độ thay đổi (rate of change) của một hàm số.
Reference